The concept of a RAG status when monitoring systems and performance is well understood. As the analyst responsible for the system, you set a threshold against a performance metric; be it CPU utilisation, memory, file system, or anything else that seems particularly interesting or pertinent to you. You then sit back and wait for the end of the day/week/month and watch the RED or AMBER threshold get breached. Excellent stuff! You can get on with more interesting things, while the system monitors itself and tells you whether anything has happened that you should pay attention to.
In large environments, where you may have many hundreds or thousands of devices that need to be monitored, then threshold based reporting is essential. No-one should be expected to continually watch graphs of device metrics on the off-chance that a utilisation gets to a level that is 'interesting'.
The problem comes with systems that are regularly doing something that would breach the thresholds that you've set. The most common instance of this is a backup. when the system backup runs there will be a very high level of CPU, Memory and IO activity. If you change your system thresholds so that this high level does not cause an alert then you will be setting things too high. A backup that causes 90% CPU isn't necessarily a problem when it occurs overnight, whereas a looping process that causes 90% CPU during the middle of your working day will be a problem. Setting the thresholds to ignore a backup will also mean that you miss that looping process. However setting your thresholds to catch the looping process means that you'll be alerted to your backups every night.
What to do?
Most people know the story of 'The boy that cried wolf'. I'm not sure that a fairy tale about 'The Capacity Manager that cried RAG' would have been quite so popular, but the concept is the same. If you are continually warning people about things that are not a problem, then they will learn to ignore what you say. They will then take no notice of you when there really is a problem.
It is not sufficient to just make a personal note to 'ignore device XYZ when it breaches' since you'll still have to check that the breach occured when you expected it to, rather than at any other time.
Maybe we should just not bother to monitor that device?
That is a little harsh! Just because a device has a regular period of known high activity you are suggesting that we exclude it from all our alerting? No, we need a more intelligent solution than that.
Exclusions
The solution that we need to employ is that of excluding specific hours of specific days from the alerting process. If we know that device XYZ is always busy doing its backup between 1am and 3am, then we exclude those hours from the alerting. This way, the high activity during those hours will not cause a RED or AMBER alert to be raised, but high activity at all other times will. This has an extra, often overlooked, benefit.
The high activity that we're trying to exclude is commonly referred to as a 'backup', it might equally be any other long running 'batch' type workload. Other examples are large mailshots, synchronising data between devices, uploading of branch data to Head Office. The key capacity measurement in these cases is not going to be how utilised the resources are, but how long it takes for the job to complete. If we return to our example above, we note that the overnight job runs between 1am and 3am. We've excluded those hours from our alerting, so we don't get prompted about problems on this device due to the overnight work. If, however, the overnight work starts to take longer and longer to complete (due to an increase in the amount of data that has to be handled), then eventually it will not complete until 3:30 or even 4am. Since we are not excluding the hours after 3am, the higher utilisation at this time will cause a RAG threshold to be breached, and we will get alerted to that fact.
We have simultaneously managed to prevent false alarms from our overnight work, while ensuring that we definitely get alerted when something happens that is 'out of the ordinary'.
I have used exclusions to great effect at many of my clients. The list of excluded devices and metrics gets reviewed once a quarter to ensure that it is still appropriate. A device might be comp;letely excluded for a few months because it is undergoing extreme stress testing; once that testing is completed we want to delete the exlcusion and resume monitoring thresholds normally. Equally, the overnight batch work of archiving old emails might be re-scheduled; our exclusion wil have to move to match the new timing.
Exclusions should be used in conjunciton with dynamic thresholds.... more about those in a future blog posting.
 ,
, ,false)*exp(
,false)*exp(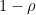 ) + Poisson(
) + Poisson(![\biggl [1 + \frac{(c\rho)^c}{c!(1-\rho)} + \sum\limits_{n=1}^{c-1} \frac{(c\rho)^n}{n!} \biggr]^{-1}=\wp_0](http://s0.wp.com/latex.php?latex=%5Cbiggl+%5B1+%2B+%5Cfrac%7B%28c%5Crho%29%5Ec%7D%7Bc%21%281-%5Crho%29%7D+%2B+%5Csum%5Climits_%7Bn%3D1%7D%5E%7Bc-1%7D+%5Cfrac%7B%28c%5Crho%29%5En%7D%7Bn%21%7D+%5Cbiggr%5D%5E%7B-1%7D%3D%5Cwp_0+&bg=ffffff&fg=000&s=0&c=20201002)
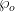 value, all other values in the M/M/c queuing theory are MUCH easier to calculate.
value, all other values in the M/M/c queuing theory are MUCH easier to calculate.
 ) )))
) )))

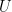 or
or 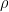 is
is 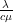 which is
which is  = 0.6667
= 0.6667![\biggl [1 + \frac{(c\rho)^c}{c!(1-\rho)} + \sum\limits_{n=1}^{c-1} \frac{(c\rho)^n}{n!} \biggr]^{-1}](http://s0.wp.com/latex.php?latex=%5Cbiggl+%5B1+%2B+%5Cfrac%7B%28c%5Crho%29%5Ec%7D%7Bc%21%281-%5Crho%29%7D+%2B+%5Csum%5Climits_%7Bn%3D1%7D%5E%7Bc-1%7D+%5Cfrac%7B%28c%5Crho%29%5En%7D%7Bn%21%7D+%5Cbiggr%5D%5E%7B-1%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\biggl [1 + \frac{(5*0.6667)^5}{5!(1-0.6667)} + \sum\limits_{n=1}^{4} \frac{(5*0.6667)^n}{n!} \biggr]^{-1}](http://s0.wp.com/latex.php?latex=%5Cbiggl+%5B1+%2B+%5Cfrac%7B%285%2A0.6667%29%5E5%7D%7B5%21%281-0.6667%29%7D+%2B+%5Csum%5Climits_%7Bn%3D1%7D%5E%7B4%7D+%5Cfrac%7B%285%2A0.6667%29%5En%7D%7Bn%21%7D+%5Cbiggr%5D%5E%7B-1%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\biggl [1 + 10.28806 + (3.3333 + 5.555555 + 6.17284 + 5.14403) \biggr]^{-1} = 0.03175](http://s0.wp.com/latex.php?latex=%5Cbiggl+%5B1+%2B+10.28806+%2B+%283.3333+%2B+5.555555+%2B+6.17284+%2B+5.14403%29+%5Cbiggr%5D%5E%7B-1%7D+%3D+0.03175&bg=ffffff&fg=000&s=0&c=20201002)